DIN-Steckverbinder haben ein Problem, sie sind spiegelsymmetrisch. Leider sind viele dieser Steckverbinder nicht durchnummeriert was die Nutzung relativ schwierig macht.
Allerdings haben wir hier einen Vorteil. Die ED-Leitung hat meistens einen Pull-Up Widerstand Richtung 5V. Somit kann man bei eingeschalteten Dekoder 5V an dieser Leitung messen. Damit das nicht jeder immer wieder machen muss, und da ich das jetzt eh gerade machen muss, hier die Belegung als Bild.
Nachdem wir auf dem 36c3 festgestellt haben, dass die ESP32-Module quasi gar nicht im Congress-WLAN funktionieren, kam der Entschluss das man eine verkabelte Lösung braucht.
Der momentane Ansatz sieht wie folgt an. An einen Raspberry Pi wird per SPI ein ATMega 8 angebunden, welcher dann per Optokoppler an das Terminal angebunden wird.
Die Idee ist wie folgt. Wir brauchen um ein DBT-03 zu emulieren nicht nur 1200/75 asynchrone Daten, sondern auch noch einige Signale, die ein UART nicht liefern kann. Zum Beispiel einen 440 Hz und einen 1700 Hz Ton, sowie einige Gleichspannungspegel.
Die naheliegende Lösung ist es einen Timer so einzustellen, dass er mit einer für das Signal passenden Frequenz Interrupts feuert und man dann den Rest in Software macht. So wurde das scheinbar auch in einigen Terminals realisiert. (z.Bsp Loewe Multitel)
SPI deshalb, weil der UART bei einigen Raspberry Pi-Modellen nicht zuverlässig funktioniert. Außerdem kann man dadurch auch den ATMega direkt programmieren. avrdude gibs auch auf den Raspberry Pi und das sollte auch direkt so den Controller flashen können, völlig unabhängig von eventuellen Bootloadern.
Der Prototyp ist noch ein wenig kostenoptimiert auf einer möglichst kleinen Platine. Natürlich kann man das auch auf eine Europlatine packen um das dann in ein original DBT-03 Gehäuse zu packen. Dann würde man zweckmäßigerweise auch gleich einen Schaltregler für die Spannungsversorgung einbauen, oder gar auf Power over Ethernet zugreifen.
Der momentane Stand dieses Projekts ist jetzt auch auf github unter https://github.com/bildschirmtext/rpi-dbt03
Hier ist mal ein Stück Doku dazu wie man in der BTX-Serversoftware von Michael Steil Seiten anlegen kann. https://github.com/bildschirmtext/bildschirmtext
Im Unterverzeichnis data finden sich weitere Unterverzeichnisse. Seiten werden etwas merkwürdig adressiert. Existiert eine Seite unter data/123/456a.cept, so kann diese als *123456# aufgerufen werden. Die Seite a muss immer existieren, weitere Folgeseiten haben dann b, c usw im Dateinamen.
Jede Seite benötigt 2 Dateien. Die .cept-Datei enthält die rohen CEPT-Dateien. Die .meta-Datei enthält Metainformationen wie Verknüpfungen, Anbieterkennungen oder Farbpaletten. Eine a.glob-Datei in einem Verzeichnis kann hier auch Werte vorbelegen.
Zunächst benötigt man das ESP-IDF Framework. Wie man das installiert wird hier erklärt: https://docs.espressif.com/projects/esp-idf/en/latest/get-started/linux-setup.html
Es ist wichtig, dass man die Umgebungsvariablen setzt wie in Punkt 4 erklärt.
Ist das Framework installiert so holt man sich den Quellcode von hier: https://github.com/bildschirmtext/esp32_dbt03
Mit make menuconfig kann man die Einstellungen der Umgebung anpassen. Dort ist zum Beispiel unter „Serial flasher config“ der serielle Port auszuwählen. (häufig /dev/ttyUSB0, kann aber auch was anderes sein. Einfach mal ls /dev/ttyUSB* eingeben, mal mit und mal ohne eingesteckten Programmer und sehen welches dazu kommt)
Im Prinzip muss man dann nur noch make ausführen welches am Ende ausgibt welchen Befehl man zum Flashen eingeben soll.
Wenn das Gerät keine WLAN-Verbindung aufbauen kann, wartet es auf die Eingabe von 1. Gibt man das ein, so bekommt man ein Menü in dem man die Einstellungen bezüglich des WLANs und der TCP/IP Verbindung zum Server.
display_chunks.c sucht in den Blöcken nach Zeiger-Längen-Tupeln die auf nicht-überlappende Bereiche zeichen und gibt diese, wenn man irgendeinen Parameter mitgibt, auf einer 256-Farbenkonsole bunt markiert aus. Die Position des Zeiger-Längen-Tupel wird oben in der gleichne Farbkombination markiert. So hat man einen guten Eindruck davon welche Elemente die Datei enthält.
split_chunks.c trennt einen Block in seine Chunks auf.
Das Problem welches dieses Programm zu lösen versucht ist es V.23 modulierte Daten zu dekodieren. Die Daten werden dabei auch in Pakete aufgeteilt. Dies ist sehr praktisch um BTX-Daten von Tonbändern zu bekommen. Die extern benötigten Pakete sind sox und zip.
Die „Installation“ ist relativ einfach. Man klont sich das Repository. Dort gibt es unter src/bin ein Verzeichnis mit den C-Programmen. Ein Aufruf von ./compile.sh übersetzt diese. Um Dateien zu konvertieren wechselt man wieder in das src-Verzeichnis und führt dort process.sh aus. Der Parameter dafür ist die WAV-Datei des Bandes. Es sollten alle von sox unterstützen Dateiformate verwendet werden können.
Als Ausgabe wird ein ZIP-Archiv erzeugt welches alle erkannten Blöcke sowie ein wenig textuelle Info über den Prozess gespeichert werden. Die Datenblöcke werden im Format Stunde-Minute-Sekunde.Millisekunde benannt. Das ermöglich eine einfach Zuordnung zu der Position in der WAV-Datei.
Die Software soll im Sinne von Freier Software frei sein, deshalb ist wie hoffentlich so gut verständlich, dass Nutzer selbst sinnvolle Änderungen daran durchführen können.
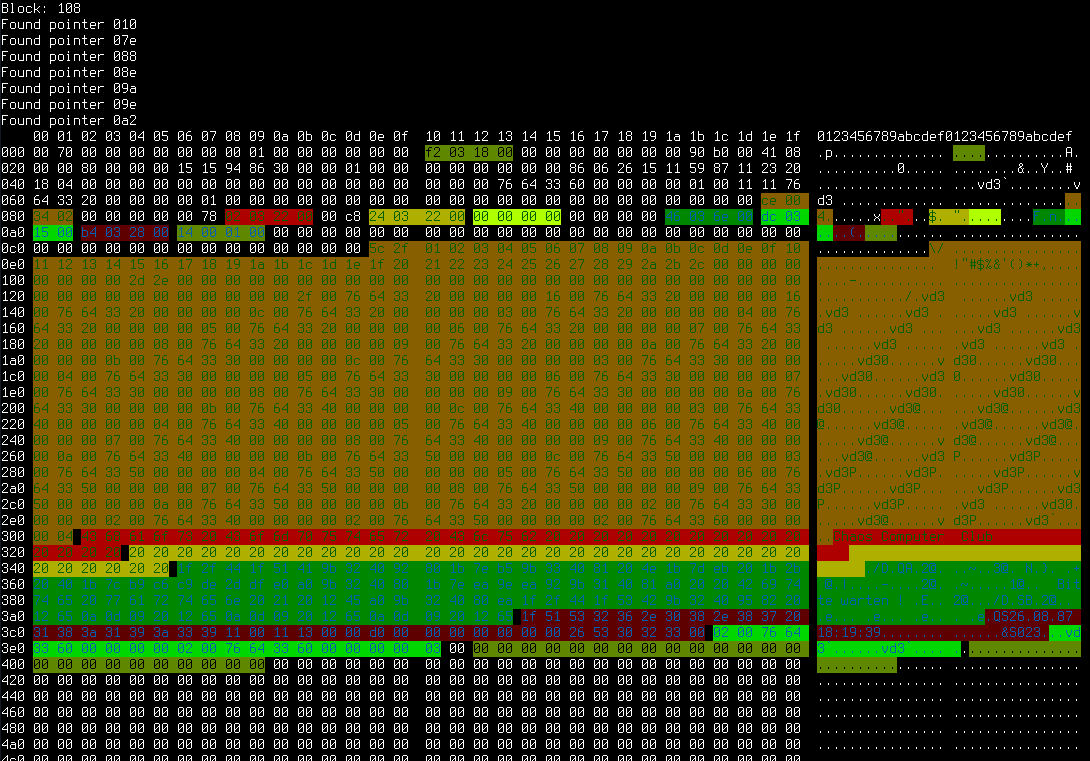
Die mir vorliegenden Dateien scheinen mehrere CEPT-Blöcke zu haben. Diese werden über Zeiger an den Offsets 0x92, 0x9a und 0xa2 referenziert. (Update: wohl auch 0xae)
Gleichzeitig scheint der ASCII-Block auch zweigeteilt zu sein und über 0x88 und 0x8e referenziert zu sein.
Die Zeiger sind jeweils 16 Bit in Intel Byteorder (least significant byte first) für die Position und die Länge.
Scheibar ist der CEPT-Block nicht 0-terminiert. Einige Daten, besonders die „Rasterfahndung“ haben 0-en in den CEPT-Daten drin. Im Offset 0x10-0x11 des Blocks ist ein Zeiger auf ein Ende der CEPT-Daten, welcher aber zumindest manchmal viel weiter nach hinten zeigt.
Scheinbar enthält aber der Anfang eines Blockes nicht nur den Zeiger auf die folgenden Daten, sondern auch noch ihre Länge. Ist in 0x92-0x93 der Zeiger zum CEPT-Block gespeichert, so enthält 0x94-0x95 seine Länge. Ist der Zeiger in 0x9a-0x9b, so ist die Länge in 0x9c-0x9d. Dies könnte ein Schlüssel zum Verständnis der Daten sein.
Es stellt sich heraus, dass das Offset zum ASCII-Text immer an Stelle 0x88-0x89 steht. Das Offset zum CEPT-Block findet sich entweder an Stelle 0x92-0x93 oder, falls da Nullen drin sind, and Stelle 0x9A-0x9B. Warum das so ist, ist mir im Moment noch nicht klar.
Wir haben einige Dateien bekommen welche wohl aus dem Programm BTX-Infotool 3 stammen. Dieses Programm diente wohl zur Erstellung von Bildschirmtextseiten und stammt von einer inzwischen nicht mehr existierenden Firma namens InfoTeSys in Düsseldorf.
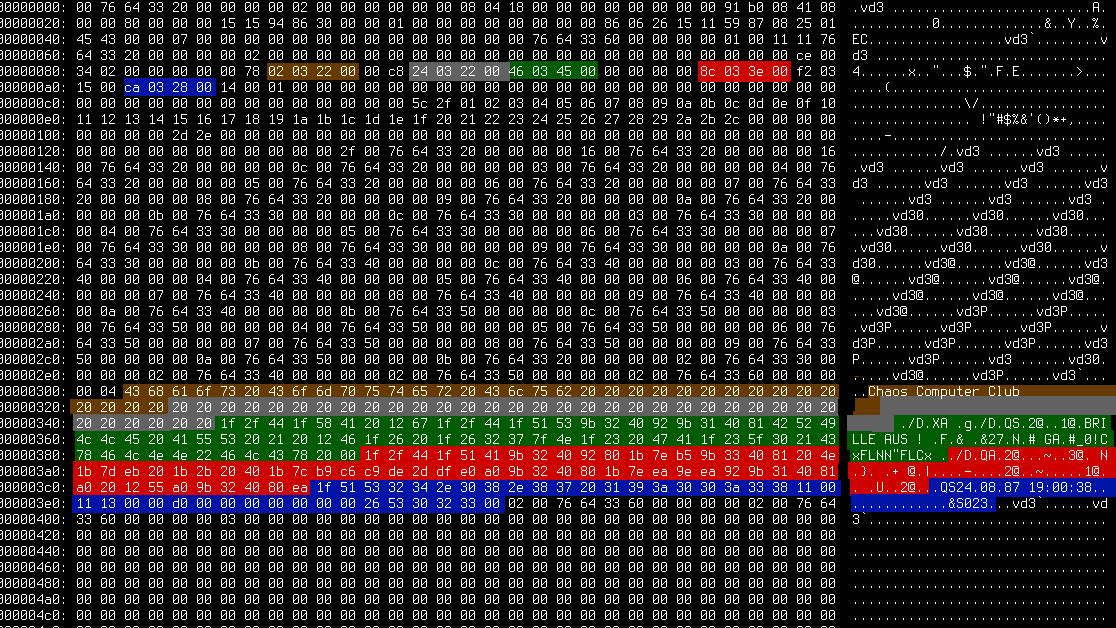
Das Dateiformat scheint Blöcke von 2048 Bytes aufzuweisen und jeder dieser Blöcke (bis auf die ersten 3) wird mit 0-Bytes aufgefüllt. Davor befinden sich die CEPT Daten. Allerdings sind diese immer an unterschiedlicher Position innerhalb des Blockes.
Ein exemplarischer Block. Man sieht am Ende das Padding mit 0-Bytes und ab Stelle 0x126 den CEPT Text. Ob der ASCII-Text davor dazu gehört ist noch unklar.